Júlia Borràs, Arnau Boix-Granell, Sergi Foix, and Carme Torras
Institut de Robòtica i Informàtica Industrial, CSIC-UPC, C/ Llorens i Artigas 4-6, 08028 Barcelona, Spain.
Abstract - Teaching complex manipulation skills, such as folding garments, to a bi-manual robot is a very challenging task, which is often tackled through learning from demonstration. The few datasets of garment-folding demonstrations available nowadays to the robotics research community have been either gathered from human demonstrations or generated through simulation. The former have the great difficulty of perceiving both cloth state and human action as well as transferring them to the dynamic control of the robot, while the latter require coding human motion into the simulator in open loop, i.e., without incorporating the visual feedback naturally used by people, resulting in far-from-realistic movements. In this article, we present an accurate dataset of human cloth folding demonstrations. The dataset is collected through our novel virtual reality (VR) framework, based on Unity’s 3D platform and the use of an HTC Vive Pro system. The framework is capable of simulating realistic garments while allowing users to interact with them in real time through handheld controllers. By doing so, and thanks to the immersive experience, our framework permits exploiting human visual feedback in the demonstrations while at the same time getting rid of the difficulties of capturing the state of cloth, thus simplifying data acquisition and resulting in more realistic demonstrations. We create and make public a dataset of cloth manipulation sequences, whose cloth states are semantically labeled in an automatic way by using a novel low-dimensional cloth representation that yields a very good separation between different cloth configurations.
Video
Examples of predicted cloth states
Dataset manipulations graph
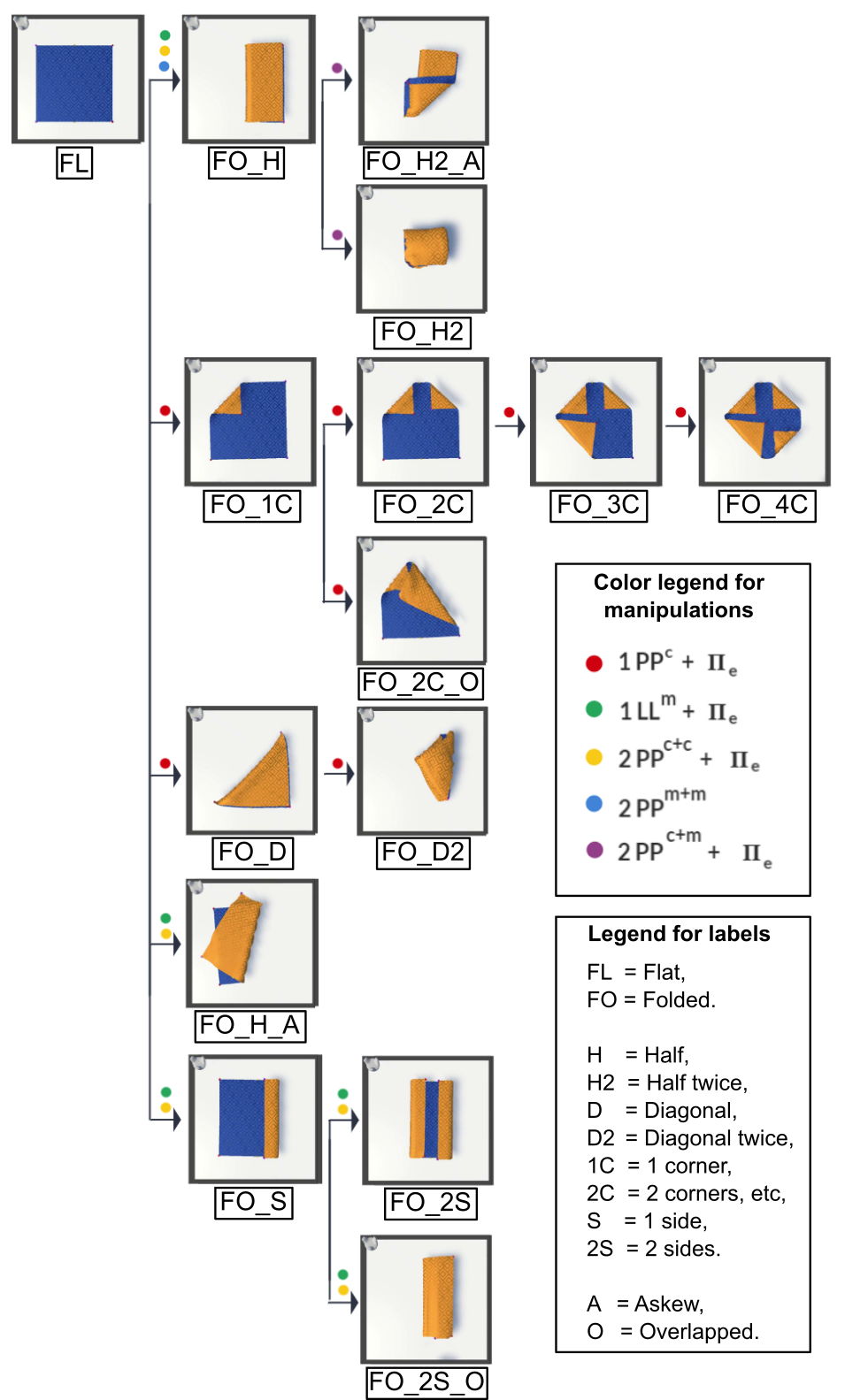
Fig. 1: Graph of state sequences, following the manipulation representation framework in [1]. The coloured dots indicate the different types of grasp types and grasp locations that can be performed to pass from the previous state to the next.
Downloads
- Virtual Reality Dataset
(VR_framework_dataset.zip)
Each XML file has the following format:
The root tag is Manipulation and has 3 main child elements: Name, mesh and Frames.
- Name contains the name of the manipulation,
- mesh contains information on the number of faces and vertices of the cloth mesh in its starting pose.
- Finally, Frames contains a list of child FrameOgre elements, one per each timestamp of the manipulation.
The element FrameOgre has 12 child XML elements.
- First, the garment name and the time stamp corresponding to the object name is being manipulated and the time stamp in seconds.
- Then 2 elements corresponding to the two controllers (left and right), with information on their position, orientation and what GripPoint they are holding, and if the trigger is activated.
- Then a list of XML elements for each GripPoint, each containing the name, its position and orientation and if its grasped by any of the controllers.
- An XML element for each tracked object, which in this case it is just the table.
- Finally, the XML element geometry contains an element vertices that has a list of child vertex elements containing its position, for each of the vertices of the mesh.
Once you obtain the mesh,you can find the function getSquaredBorder() in the provided code to obtain the border. - Labeled Dataset
(Labeled_dataset.zip)
Each CSV file contains N rows corresponding to N frames of the simulation manipulation. Each row is a 259 dim vector containing:
- 76x3 numbers corresponding to 76 3D coordinates of the points of the border,
- 28 numbers corresponding to dGLI coordinates
- 3 strings in "" corresponding to grasp1, grasp2 and predicted class
Coordinates indexes:
- 1 to 228: 76 3D points of the border,
- 229 to 256: dGLI coords,
- 257: string label for grasp 1,
- 258: string label for grasp 2,
- 259: string label for predicted class
- Jupyter Notebook Code - Functions to compute the dGLI coordinates (FunctionsDGLI.ipynb) - Functions to load a mesh from the XML file (Functions_XML_Loading.ipynb) - XML file example for running Functions_XML_Loading.ipynb (1PC_1PC_1PC_1PC_03_01.xml)
Acknowledgments
The research leading to these results receives funding from the European Research Council (ERC) from the European Union Horizon 2020 Programme under grant agreement no. 741930 (CLOTHILDE: CLOTH manIpulation Learning from DEmonstrations) and project SoftEnable (HORIZON-CL4-2021-DIGITAL-EMERGING-01-101070600). Authors also received funding from project CHLOE-GRAPH (PID2020-118649RB-I00) funded by MCIN/ AEI /10.13039/501100011033 and COHERENT (PCI2020-120718-2) funded by MCIN/ AEI /10.13039/501100011033 and cofunded by the ”European Union NextGenerationEU/PRTR”.
Bibliography
[1] I. Garcia-Camacho, J. Borràs, and G. Alenyà. Knowledge representation to enable high-level planning in cloth manipulation tasks. ICAPS 2022 Workshop on Knowledge Engineering for Planning and Scheduling, 2022.
Citation
(BibTeX)
@INPROCEEDINGS{BorrasICRA23,
author={Borràs, Júlia and Boix-Granell, Arnau and Foix, Sergi and Torras, Carme},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, London, UK},
title={A virtual reality framework for fast dataset creation applied to cloth manipulation with automatic semantic labelling},
year={2023},
volume={},
number={},
pages={xxxx-xxxx},
doi={}}