Adria Colome and Carme Torras
Policy Search (PS) algorithms are nowadays widely used for their simplicity and effectiveness in finding solutions for robotic problems. However, most current PS algorithms derive policies by statistically fitting the data from the best experiments only. This means that those experiments yielding a poor performance are usually discarded or given too little influence on the policy update. In this paper, we propose a generalization of the Relative Entropy Policy Search (REPS) algorithm that takes bad experiences into consideration when computing a policy. The proposed approach, named Dual REPS (DREPS), following the philosophical interpretation of the duality between good and bad, finds clusters of experimental data yielding a poor behavior and adds them to the optimization problem as a repulsive constraint. Thus, considering there is a duality between good and bad data samples, both are taken into account in the stochastic search for a policy. Additionally, a cluster with the best samples may be included as an attractor to enforce faster convergence to a single optimal solution in multi-modal problems. We first tested our proposed approach in a simulated Reinforcement Learning (RL) setting and found that DREPS considerably speeds up the learning process, especially during the early optimization steps and in cases where other approaches get trapped in between several alternative maxima. Further experiments in which a real robot had to learn a task with a multi-modal reward function confirm the advantages of our proposed approach with respect to REPS.
EXPERIMENT 1: Multi-modal 2D reward function (Section III.A)
A multi-modal reward function is implemented as shown in the paper. Then, with an initial policy having a normal distribution of zero mean and identity variance, both REPS and the proposed DREPS are applied. Figure 1 simultaneously shows the evolution of the policies obtained with REPS and DREPS:
Fig. 1: Comparison of REPS and DREPS for a multi-modal two-dimensional problem
Additionally to the learning curve in Fig. 7 in the paper, showing mean and standard deviation, Fig. 2 plots the learning curves by showing the mean and the Standard Error of the Mean (SEM), with the 95% confidence that the means are within the intervals shown.
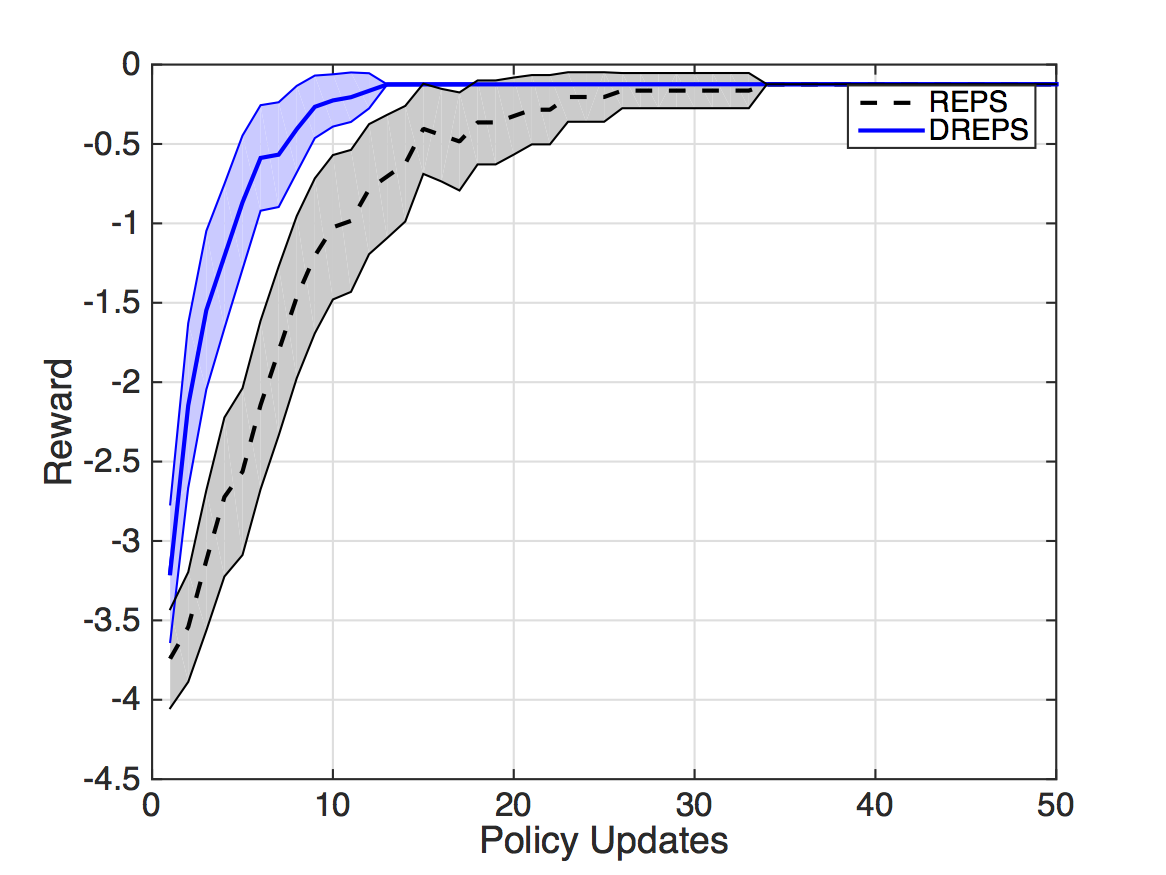
Fig. 2: Learning curves for the experiment in Section III.A showing mean and SEM for a 95% confidence interval.
Reward inverse scaling
Although it should be noted that the particular clustering algorithm used is not the main contribution in the article , we propose a 2-step clustering procedure. Parameters and rewards are appended, but they needed to be set in a common scale for these data to be later clustered. Otherwise, either the parameters or rewards may have too much importance in the clustering magnitudes. For the repulsive clusters, we used an inverse value of the reward in order to better discriminate between the clusters. The video in Fig. 3 shows the differences between using the reward or its inverse when clustering. In the early policy search updates, using the same attractor cluster (shown in green), we compare the proposed clustering with the inverse reward used for the repulsive Gaussians (in red) versus those obtained by using a 1-step only clustering (in magenta). The video shows that using such inversion helps to better discriminate the low-performing regions in the sample space.
Fig. 3: Usage of the inverse of the reward and its effect on clustering.
Testing clustering robustness
To assess the sensitivity of clustering to different samplings, we also computed the proposed clustering through several policy updates. In the video in Fig. 4, 1000 samples were evaluated and clustered for each policy update. We show the centers of the attractor cluster (in black) and the repulsive clusters (in gray) obtained through the proposed clustering. Then, we split the 1000 samples in 10 subsets of 100 samples and cluster these 10 subsets independently. The centers obtained with these 10 clustering are also shown with attractor centers in green, and repulsive centers in magenta. We can see that the attractor centers may differ at the early stages in selecting the best cluster, but such cluster is always located in one of the candidates as an optimal solution, thus showing the ability of DREPS to avoid averaging between solutions.
Fig. 4: Clustering sensitivity for different samplings
Testing scalability to higher dimensions
The above 2D problem was generalized to dimension 10, with the same points projected to a higher-dimensional space. In Fig. 5, we see that, despite not showing as much difference, DREPS still outperforms REPS. The reduction in difference is due to the less restrictive reward function when the same points are embedded into a higher-dimensional space.
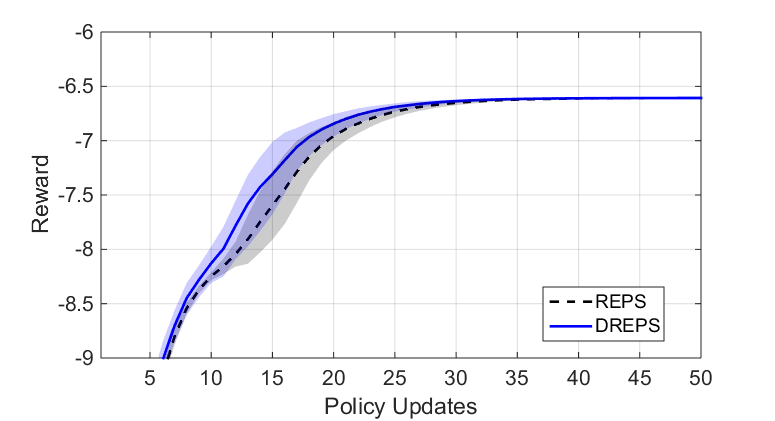
Fig. 5: Learning curves showing the reward evolution in the 10-dimensional problem. The plot shows the mean and standard deviation over 50 learning experiments.
EXPERIMENT 2: Real robot multi-modal problem (Section III.B)
We implemented a robotic trajectory using a Barrett WAM robot, which would go in a straight line with fixed orientation (facing down) and fixed z component from a starting position towards a goal position. Two bottles were added on the way as seen in the paper.
In Fig. 6, we can see the evolution of the policy in two learning executions using REPS and DREPS with the same settings. The bottles are depicted as black circles with a safety threshold representing the robot wrist, while the rollouts are shown in grey and the new policies in blue. Fig. 7 shows the final trajectoy obtained with DREPS, executed in the real robot.
Fig. 6: Comparison of two learning executions, one using REPS and another one using DREPS
Fig. 7: Final trajectory obtained by learning with DREPS