pdf / bibref / poster
- 1 Institut de Robòtica i Informàtica Industrial (Barcelona, Spain)
Note: the code for this project is not "user-friendly" in its current state, but I'll put it up sometime. Ping me if you're interested.
Matching two sets of descriptors is usually performed by computing the distances between the possible correspondences, and then applying a global optimization algorithm (e.g. graph cuts) to enforce spatial consistency. This is the most common approach for stereo reconstruction, and similar procedures can be applied to object recognition or classification, or optical flow. But the problem can be too challenging in scenes with poor texture or repetitive patterns aligned with the epipolar geometry. In controlled settings, the correspondence problem can be further relaxed via structured-light patterns. Otherwise, more sophisticated descriptors need to be designed. In such situations we can attempt to incorporate dynamic information to further discriminate amongst possible matches.
Appearance descriptors based on histograms of gradient orientations, such as SIFT or Daisy [1], can be extended by computing histograms over the spacetime volume. Since the local temporal structure depends strongly on the camera view, most efforts in this direction have focused on monocular action recognition. For stereo reconstruction, spatiotemporal descriptors computed in this manner should be oriented according to the geometry of a particular setup. This approach was applied by Sizintsev et al (CVPR'09) to design the stequel primitive [2], which is applicable to short-baseline stereo.
We want to face the problem from a different angle. We have designed a spatiotemporal approach to 3D stereo reconstruction applicable to wide-baseline stereo, augmenting the 2D—i.e. spatial—descriptor with optical flow priors [4] instead of computing 3D—i.e. spatiotemporal—gradients or similar primitives. We intend to compute, for each camera, dense Daisy descriptors for a frame, and then extend them over time with optical flow priors, while discarding incorrect matches, effectively obtaining for every pixel a concatenation of spatial descriptors across different times. These descriptors can then be matched in the traditional manner, and a global optimization algorithm is applied over the spatiotemporal structure to enforce spatial and temporal consistency. The core idea behind our approach is to develop a primitive that captures the evolution of the spatial structure around a feature point in time, instead of trying to describe the spatiotemporal volume, as the latter cannot be generalized to wide-baseline due to the change of perspective and occlusions.
We construct our spatiotemporal descriptor in the following way. We use the spatial Daisy grid to compute the sub-descriptor over the feature point on the central frame. We then warp the grid by means of the optical flow priors, and compute a new sub-descriptor using the warped grid for each frame. We match each sub-descriptor computed with the warped grid against the sub-descriptor for the central frame, and discard it if the matching score falls above a certain threshold—this way we can validate the optical flow and discard a match if the patch suffers large transformations. The descriptor is assembled concatenating valid sub-descriptors.
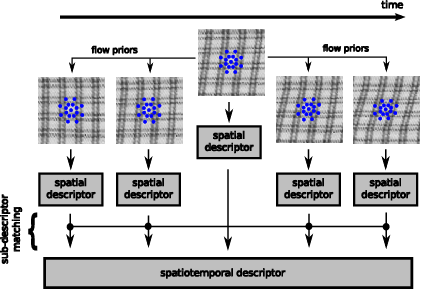
Computation of the spatiotemporal descriptor with flow priors. Sub-descriptors outside the central frame are computed with the warped grid, and validated against the original frame.
We apply this descriptor to stereo, using a pair of calibrated monocular cameras. We compute descriptors along epipolar lines, using the calibration data to rotate the grid. We discretize 3D space, compute the depth for every possible correspondence and store the best match for every depth bin, building a hypercube of matching scores of size W x H x L x M, where W and H are the width and height of the image, L is the number of layers used to discretize 3D space and M is the number of consecutive frames under consideration (e.g. 5-7). We want to enforce piecewise-smoothness, which is NP-hard—we apply off-the-shelf Graph Cuts [3] with the distances as matching costs. To enforce spatiotemporal consistency we apply the smoothing function over space-time, linking each pixel (x,y,t) to its 4 adjacent neighbors over the spatial domain and the two pixels that share its spatial coordinates on two adjacent frames, (x,y,t-1) and (x,y,t+1).
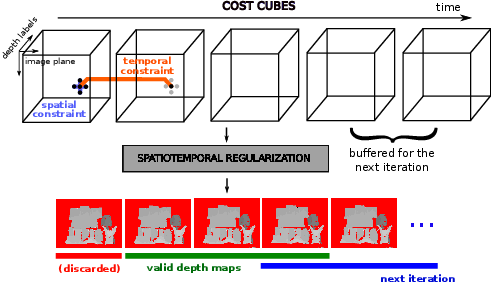
To perform spatiotemporal regularization, we apply graph cuts over a hypercube of costs (displayed here as a series of cubes). We set spatial and temporal pairwise relationships for the smoothness function. We discard the depth maps at either end of the buffer, to avoid singularities—note that we do not need to recompute the cost cubes.
The paper demonstrates the effectiveness of our approach against SIFT, Daisy and Stequel, for wide-baseline setups, on highly ambiguous data, and against image noise.
Results for a real sequence
Results for a synthetic sequence: noise
Results for a synthetic sequence: baseline (1/2)
Results for a synthetic sequence: baseline (2/2)
References
- [1] E. Tola, V. Lepetit, P. Fua. Daisy: An efficient dense descriptor applied to wide-baseline stereo. T.PAMI, 2010.
- [2] M. Sizintsev, R. Wildes. Spatiotemporal stereo via spatiotemporal quadric element (stequel) matching. CVPR, 2009.
- [3] Y. Boykov, O. Veksler, R. Zabih. Fast approximate energy minimization via graph cuts. T. PAMI, 2001.
- [4] C. Liu. Beyond pixels: Exploring new representations and applications for motion analysis. PhD Thesis, 2009.