Supplementary material
Action Recognition based on Efficient Deep Feature Learning in the Spatio-Temporal Domain
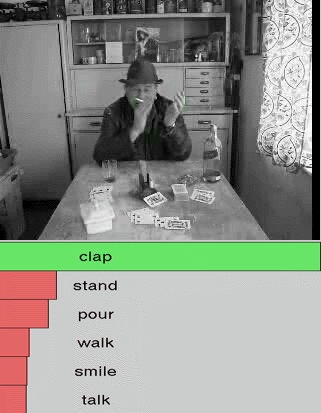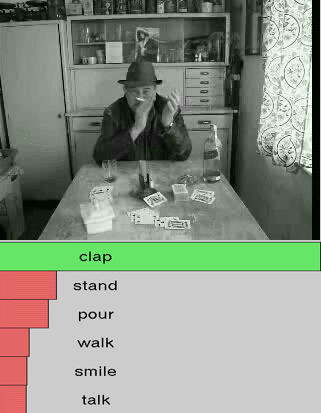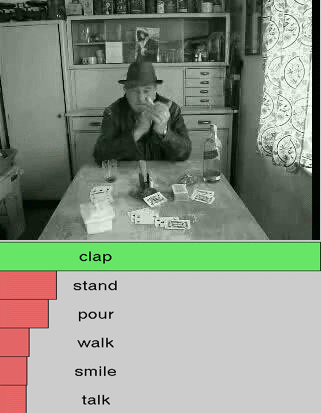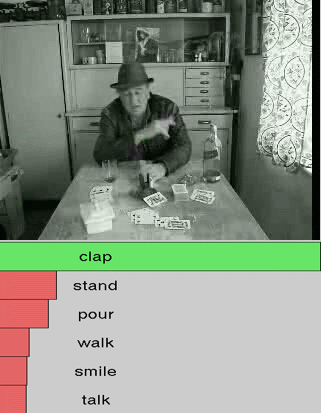
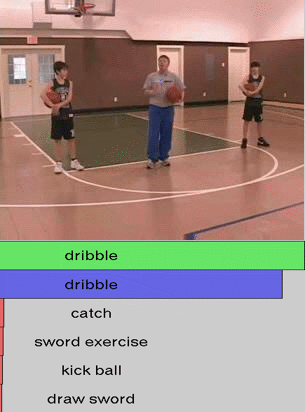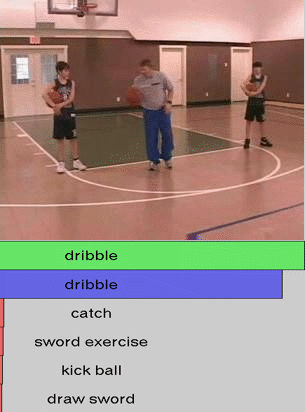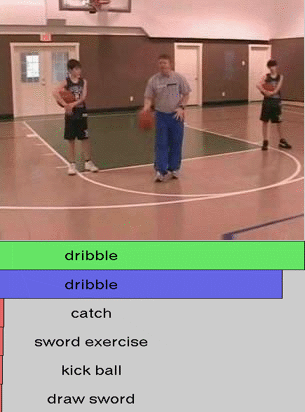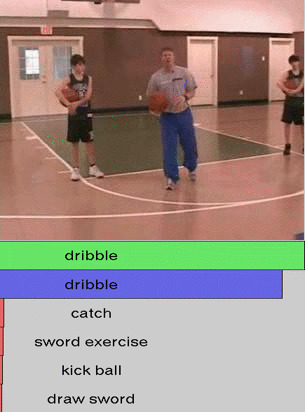
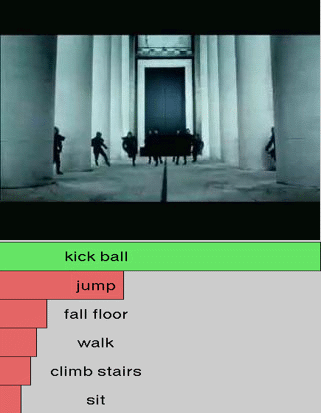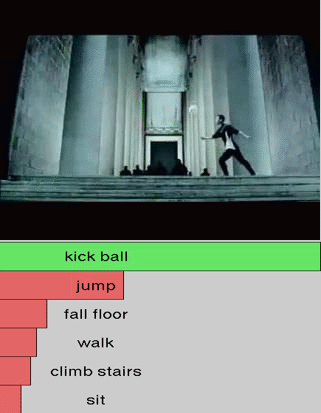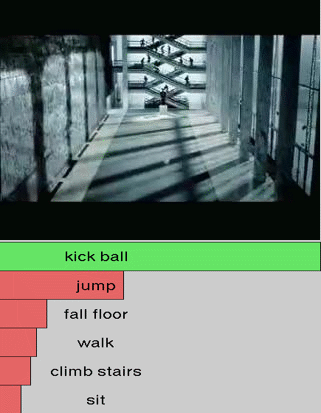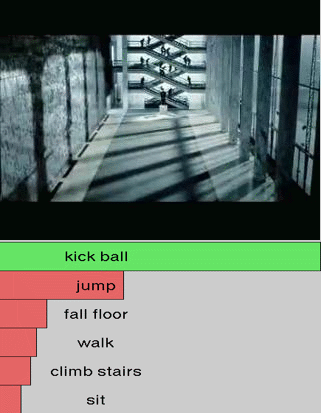
We show additional results for selected 25 test videos from the third split of the HMDB-51 dataset
with 51 action categories. First row (green color) shows the
ground-truth followed by predictions in decreasing level of confidence.
Blue and red show correct and incorrect predictions, respectively.