David Martínez, Guillem Alenyà, Pablo Jiménez, Carme Torras, Jürgen Rossmann, Nils Wantia, Eren Erdal Aksoy, Simon Haller, Justus Piater
Introduction
We describe a system allowing a robot to learn goal-directed manipulation sequences such as steps of an assembly task. Learning is based on a free mix of exploration and instruction by an external teacher, and may be active in the sense that the system tests actions to maximize learning progress and asks the teacher if needed. The main component is a symbolic planning engine that operates on learned rules, defined by actions and their pre- and postconditions. Learned by model-based reinforcement learning, rules are immediately available for planning. Thus, there are no distinct learning and application phases. We show how dynamic plans, replanned after every action if necessary, can be used for automatic execution of manipulation sequences, for monitoring of observed manipulation sequences, or a mix of the two, all while extending and refining the rule base on the fly. Quantitative results indicate fast convergence using few training examples, and highly effective teacher intervention at early stages of learning.
Experimental scenarios
Two different experimental scenarios are considered:
|
|
|---|---|
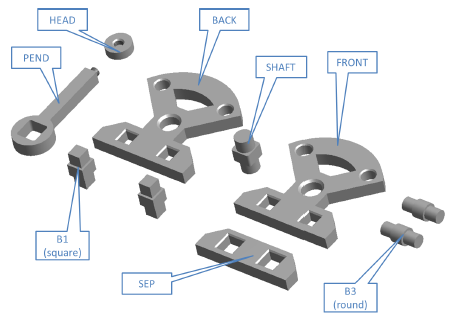
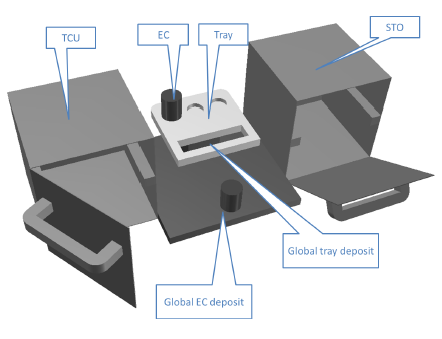
| The AUTAS scenario consists of the Cranfield assembly benchmark. The sequence in which the parts have to be assembled is conditioned by the precedence constraints in the assembly. These constraints have to be learned from sequences leading to successful completions of the assembly. | The LABEX scenario represents a laboratory environment in the International Space Station (ISS) where a scientific experiment takes place. The setting includes two cupboards, one of which should remain closed as long as possible in order to keep the temperature constant (TCU), and the other one has compartments at different temperatures (STO), plus some experimental containers (EC) which can be transported on trays from and to the cupboards and the global deposit. |
Method
|
1.Action demontration: human demonstrates (in a VR environment) a sequence of action to solve a given task. An activity recognition module recognises unitary actions and the learner module generates new rules describing each action. |
|
2.Learning and execution: The system finds a plan and tries to execute it. Due to the partial knowledge, some actions cannot be executed. These failures are used to refine the rules (preconditions, effects, and success). We emulate the functioning of a real robotic system by incorporating failures in the execution of an action. The source of such failures is either related to perception noise (i.e., during the segmentation and recognition processes, consisting in misidentified parts or in missing objects) or to action noise (during robot execution, e.g.\ failed grasps or insertions, dropped parts, or dead ends). In all cases, the result is that the outcome of an action is not as expected, and additional demonstrations by the teacher may be required to learn the task |
|
3.Monitoring As an additional feature, the system can be used to monitor a human trying to solve the task using the set of learned rules. After each action the system detects if a suitable plan can be found, if the current status is closer to the resolution of the task, and propose to the human the next action. |
Source code
The source code for the REX-D algorithm can be downloaded here: rex-d.zip.
The documentation can be found here: rex-d documentation.
If you have any question or suggestion, don't hesitate to contact me: dmartinez[at]iri.upc.edu.
Literature
This work is presented in:
- Active Learning of Manipulation Sequences, David Martínez, Guillem Alenyà, Pablo Jiménez, Carme Torras, Jürgen Rossmann, Nils Wantia, Eren Erdal Aksoy, Simon Haller, Justus Piater. In International Conference on Robotics and Automation, 2014, pp. 5671-5678. PDF
- Manipulation monitoring and robot intervention in complex manipulation sequences, Thiusius R. Savarimuthu, Anders G. Buch, Yang Yang, Wail Mustafa, Simon Haller, Jeremie Papon, David Martínez, Eren E. Aksoy. In Workshop on Robotic Monitoring (at the Robotics: Science and Systems conference), 2014. PDF
- Relational Reinforcement Learning with Guided Demonstrations, David Martínez, Guillem Alenyà, Carme Torras. 2015. Artificial Intelligence.