David Martínez, Guillem Alenyà, Carme Torras
Introduction
Task learning in robotics is very time consuming, and model-based reinforcement learning algorithms have been proposed to learn with just a small amount of experiences. However, reducing the number of experiences used to learn implies that the algorithm may overlook important actions that may be required to get an optimal behaviour, for example a robot may learn simple policies that have higher risk of not reaching the goal (i.e. falling into a dead-end). We propose a new method that allows the robot to analyze dead-ends and their causes to avoid them. Using the currently available model and experiences, the robot will hypothesize the possible causes of the dead-end, and identify the actions that may cause it. Whenever a dangerous action is planned and it has high risk of leading to a dead-end, the robot will actively confirm with a teacher that the planned action should be executed, and request a demonstration if the action is not considered to be safe by the teacher. This permits learning safer policies with the addition of just a few teacher demonstration requests.
Experimental scenario
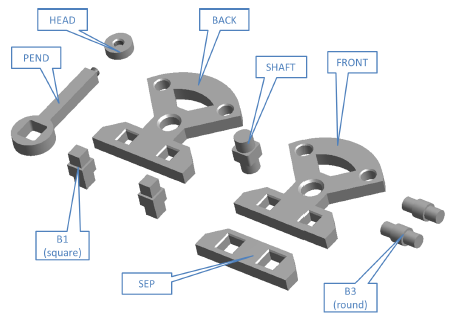
The Cranfield benchmark was selected to perform the experiments:
|

|
|---|---|
| The sequence in which the parts have to be assembled is conditioned by the precedence constraints in the assembly. These constraints have to be learned from sequences leading to successful completions of the assembly. |
Method
|
1.Cranfield benchmark execution: The robot completes the Cranfield benchmark using the actions planned by the decision maker. As the scenario has been already learned in previous episodes, it manages to complete it with no failures. |
|
2.Learning how to reposition a peg: The robot knows that placing a vertical peg usually success, but that placing a horizontal peg will surely fail. However, when a peg falls into a horizontal position, the robot doesn't know how to reposition it to a vertical position, and therefore requests help to the teacher. The teacher demonstrates how to reposition the peg to be vertical and the robot learns it. |
Literature
This work is presented in:
- Learning Safe Policies in Model-Based Active Learning, David Martínez, Guillem Alenyà, Carme Torras. Submitted.