Learned Vertex Descent: A New Direction for 3D Human Model Fitting
Enric Corona, Gerard Pons-Moll, Guillem Alenyà, Francesc Moreno-Noguer
ECCV 2022
description Paper description Project play_circle_filled Video code Code
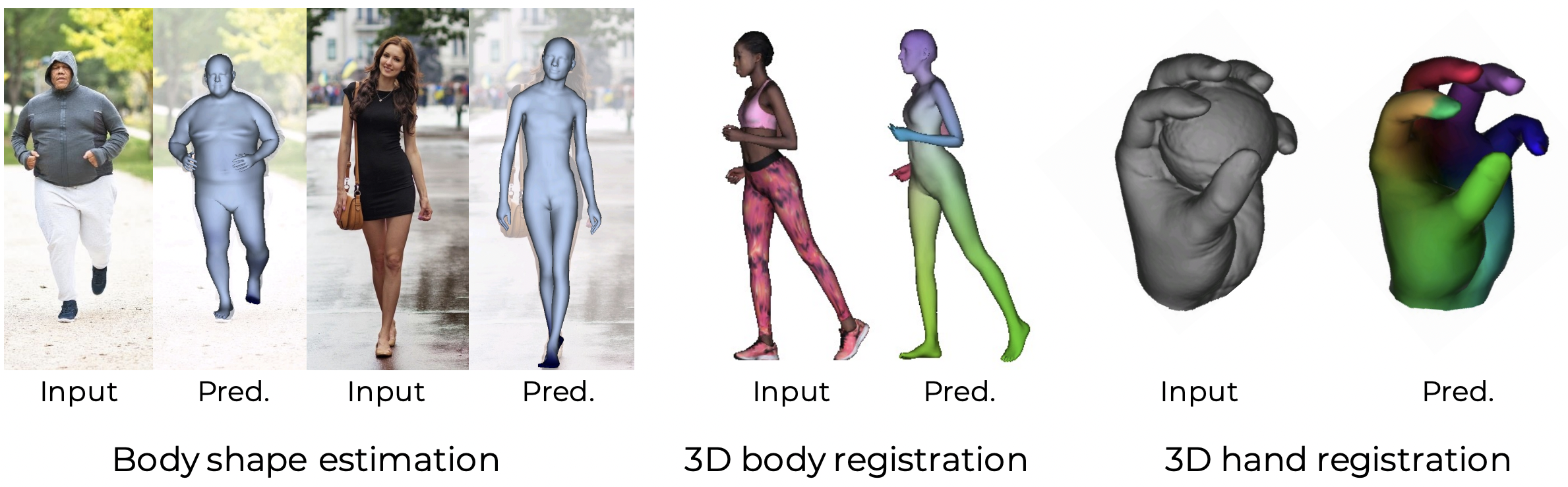
Abstract
We propose a novel optimization-based paradigm for 3D human model fitting on images and scans. In contrast to existing approaches that directly regress the parameters of a low-dimensional statistical body model (e.g. SMPL) from input images, we train an ensemble of per vertex neural fields network. The network predicts, in a distributed manner, the vertex descent direction towards the ground truth, based on neural features extracted at the current vertex projection.
At inference, we employ this network, dubbed LVD, within a gradient-descent optimization pipeline until its convergence, which typically occurs in a fraction of a second even when initializing all vertices into a single point. An exhaustive evaluation demonstrates that our approach is able to capture the underlying body of clothed people with very different body shapes, achieving a significant improvement compared to state-of-the-art. LVD is also applicable to 3D model fitting of humans and hands, for which we show a significant improvement to the SOTA with a much simpler and faster method.
How does LVD work?
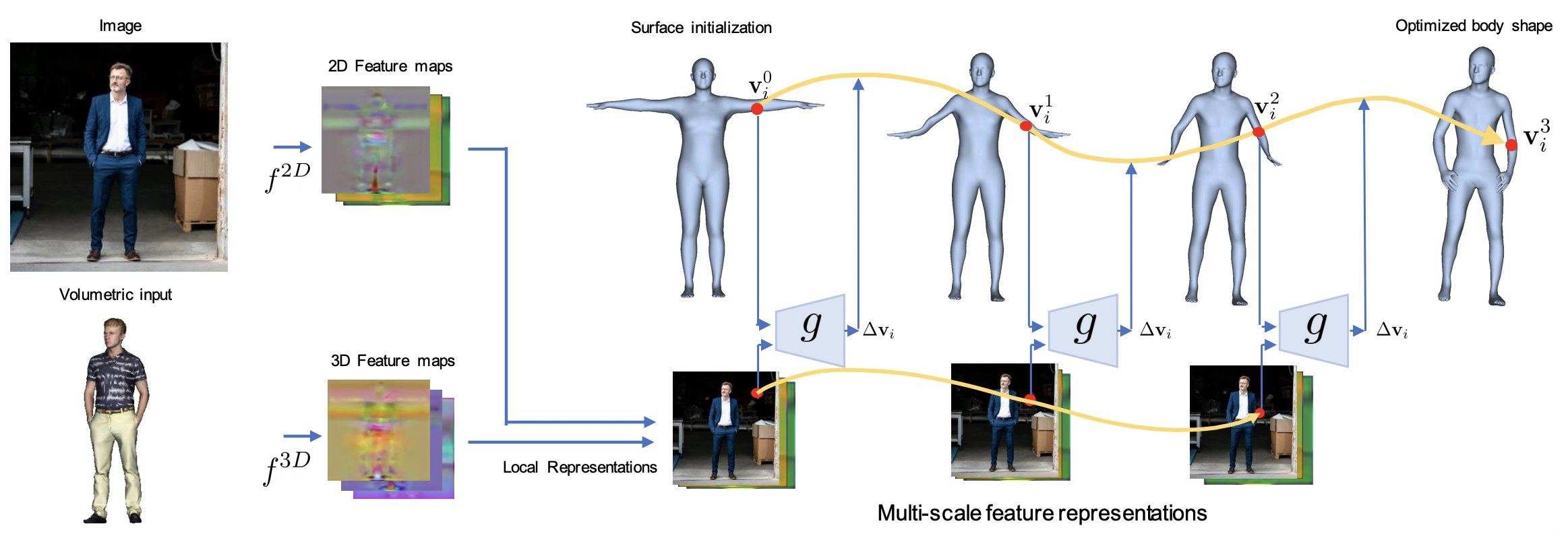
LVD is a novel framework for estimation of 3D human body where local features drive the direction of vertices iteratively by predicting a per-vertex neural field. At each step, the network takes an input vertex to obtain its corresponding local features, and predict the direction towards its groundtruth position. The surface initialization here follows a T-Posed body, but the proposed approach is very robust to different initializations.
The features are formed by representations extracted at different levels of the encoding network, and therefore include both local and global information. This approach is flexible and can be based on 3D or 2D features, and we evaluate it on the tasks of SMPL estimation from images or 3D pointclouds, and MANO estimation from 3D pointclouds.
Applications
Estimation of SMPL from images:
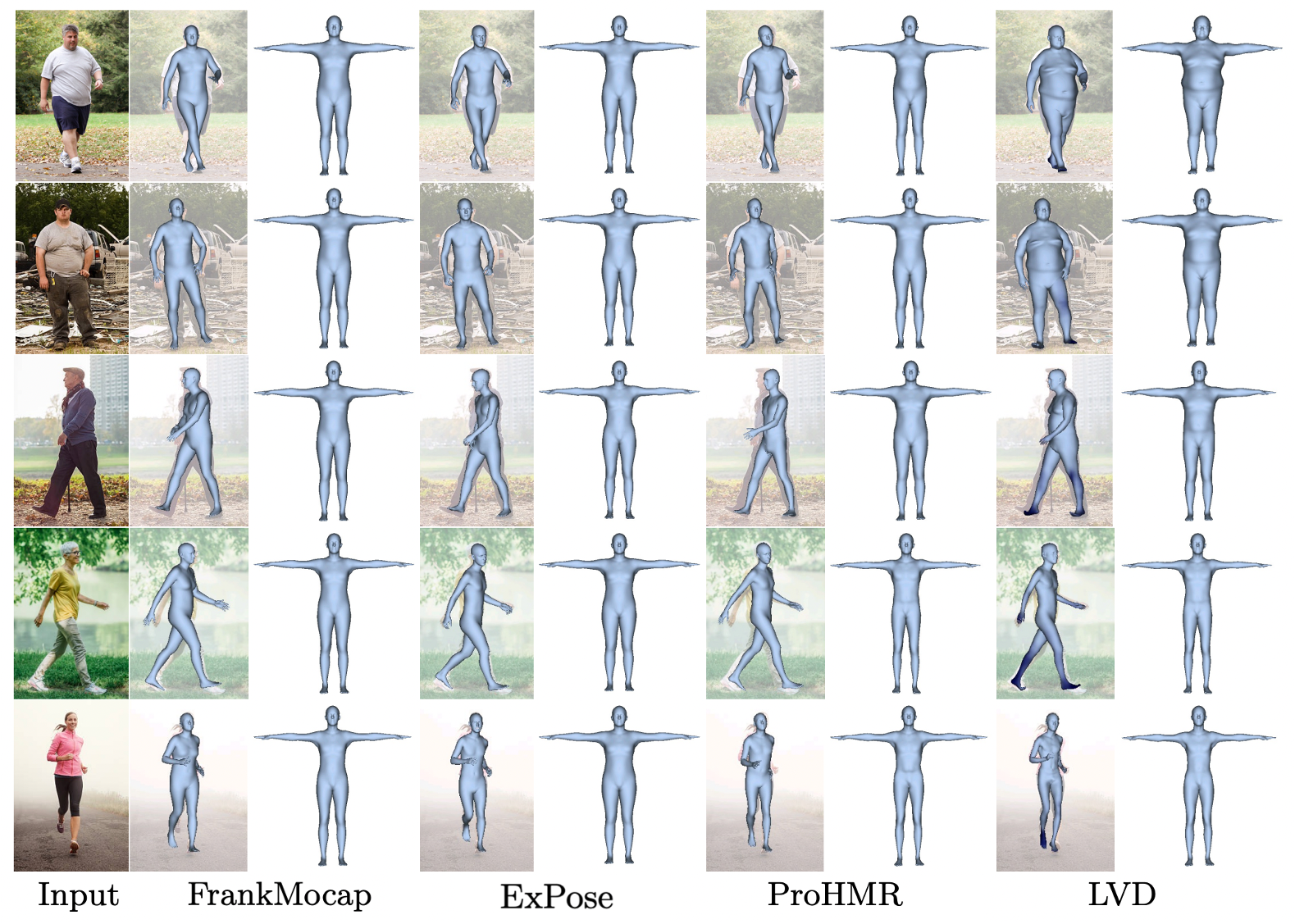
We first evaluate LVD on the task of SMPL estimation on images on-the-wild, by giving more importance to the estimation of different shapes. The model is trained on the renderpeople dataset and learns to predict a diverse distribution of SMPL body shapes from a very small set of training, in contrast to previous works in SMPL estimation that were trained on big collections of real images.
For each method, we here show the reconstruction in posed and canonical space. While previous works focus on pose estimation, they are prone to generate always an average body shape. In contrast, LVD generates a much richer distribution of body shapes as shown in the right-most column.
Estimating SMPL from 3D pointclouds:
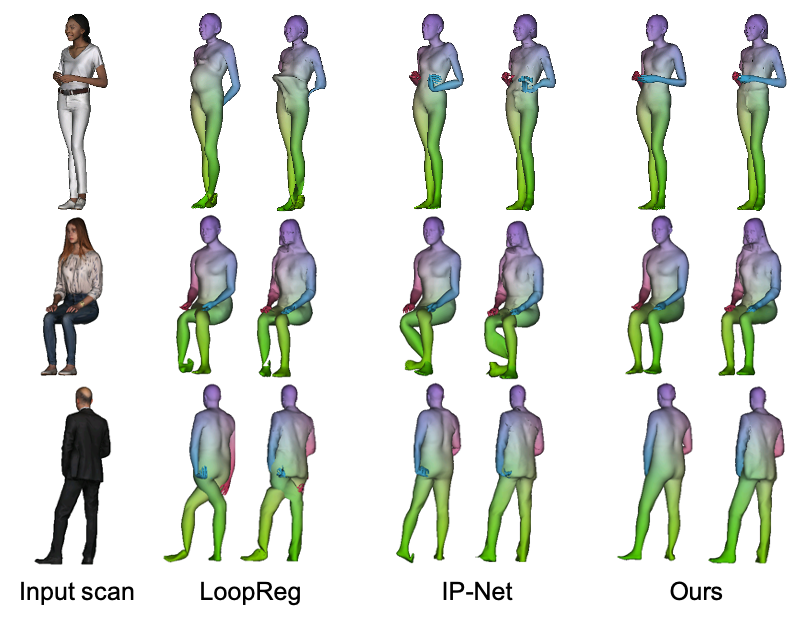
We next evaluate how we can estimate SMPL and SMPL+D on 3D scans of humans by taking point clouds as input. The initial SMPL estimation from LVD is already very competitive against state-of-the-art baselines. By using these predictions as initialization for SMPL/SMPL+D registration without further correspondences, we obtain ∼28.4% and ∼37.7% relative improvements with respect to the second-best method in joint and SMPL vertex distances respectively.
Estimating MANO from 3D pointclouds:
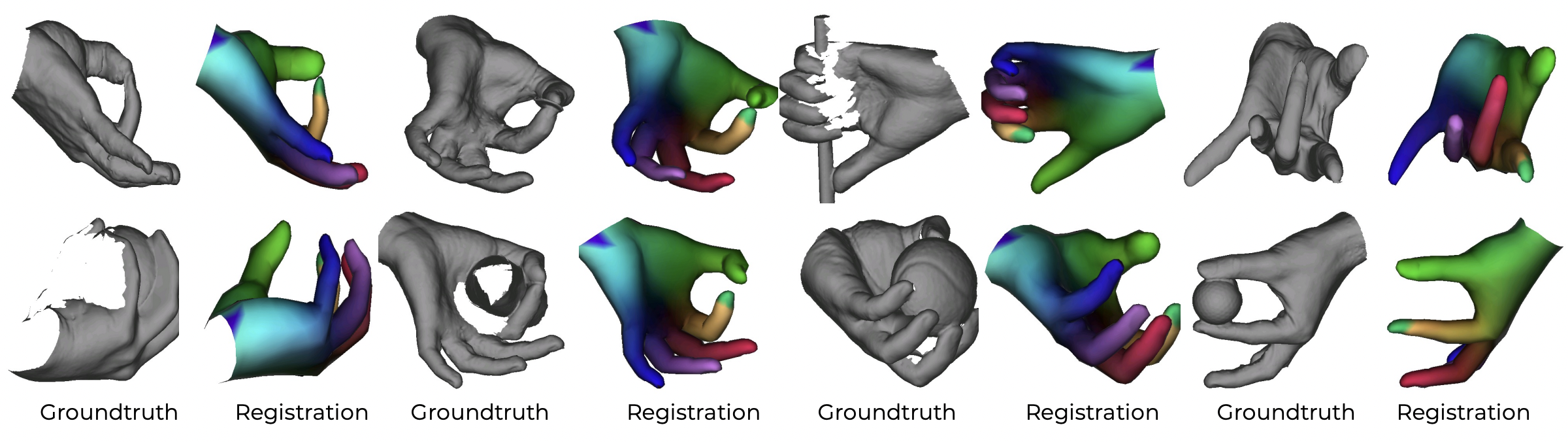
Finally, LVD can be used easily on different parametric models. In this case, we adapt it to MANO only by changing the number of vertices with respect to SMPL, and train it to register MANO from input pointclouds where it also outperforms all baselines.
Publication

Learned Vertex Descent: A New Direction for 3D Human Model Fitting
Enric Corona, Gerard Pons-Moll, Guillem Alenyà, Francesc Moreno-Noguer
Project Page Paper Supplementary Code Bibtex
@inproceedings{corona2022lvd,
Author = {Corona, Enric and Pons-Moll, Gerard and Alenyà, Guillem and Moreno-Noguer, Francesc}
Title = {Learned Vertex Descent: A New Direction for 3D Human Model Fitting},
Year = {2022},
booktitle = {ECCV},
}
Citation
@inproceedings{corona2022lvd,
Author = {Corona, Enric and Pons-Moll, Gerard and Alenyà, Guillem and Moreno-Noguer, Francesc}
Title = {Learned Vertex Descent: A New Direction for 3D Human Model Fitting},
Year = {2022},
booktitle = {ECCV},
}